Workflow
Basic Workflow
The basic workflow for the rainfall model consists of the following steps:
Initialise a model
Preprocess time series data (e.g. from a gauge(s)) to calculate “reference statistics”
Fit model parameters to reference statistics
Simulate one or more stochastic time series
Postprocess simulation to calculate/extract relevant statistics
Note
The term “reference statistics” is used instead of “observed statistics” or “gauge statistics” in preparation for e.g. climate change scenarios based on perturbed statistics.
More detailed Examples are given separately, but in outline terms the basic workflow can consist of something like (for a single site model):
import rwgen
# Initialise rainfall model
rainfall_model = rwgen.RainfallModel(
spatial_model=False,
project_name='brize_norton',
)
# Calculate reference statistics from gauge time series
rainfall_model.preprocess(
input_timeseries='./input/brize_norton.csv',
)
# Fit model parameters using reference statistics
rainfall_model.fit()
# Simulate five realisations of 1000 years at an hourly timestep
rainfall_model.simulate(
simulation_length=1000,
n_realisations=5,
timestep_length=1,
)
# Calculate/extract statistics from simulated time series (e.g. AMAX, DDF)
rainfall_model.postprocess(
amax_durations=[1, 6, 24], # durations in hours
ddf_return_periods=[20, 50, 100] # return periods in years
)
Explanation
In the example above we initialise a RainfallModel, which contains the
underlying preprocessing, fitting, simulation and post-processing
functionality. By creating an instance of RainfallModel, we can specify
input files, choose various options and then carry out a set of specific
tasks (e.g. using fit() to find suitable model parameters).
In Python terminology, RainfallModel is a class. An instance of a class
(in our case the object rainfall_model) can have methods and attributes.
An attribute is a variable that “belongs” to the model, such as an option that
we have set (e.g. project_name) or some other data. Attributes are
retained by the model until we change them (typically through a method call).
Methods are like functions, but they can also modify the attributes of an
object.
The structure of RainfallModel and the basic workflow is shown by the
“CORE METHODS” column in the diagram below. Dashed arrows indicate the basic
workflow using these methods.
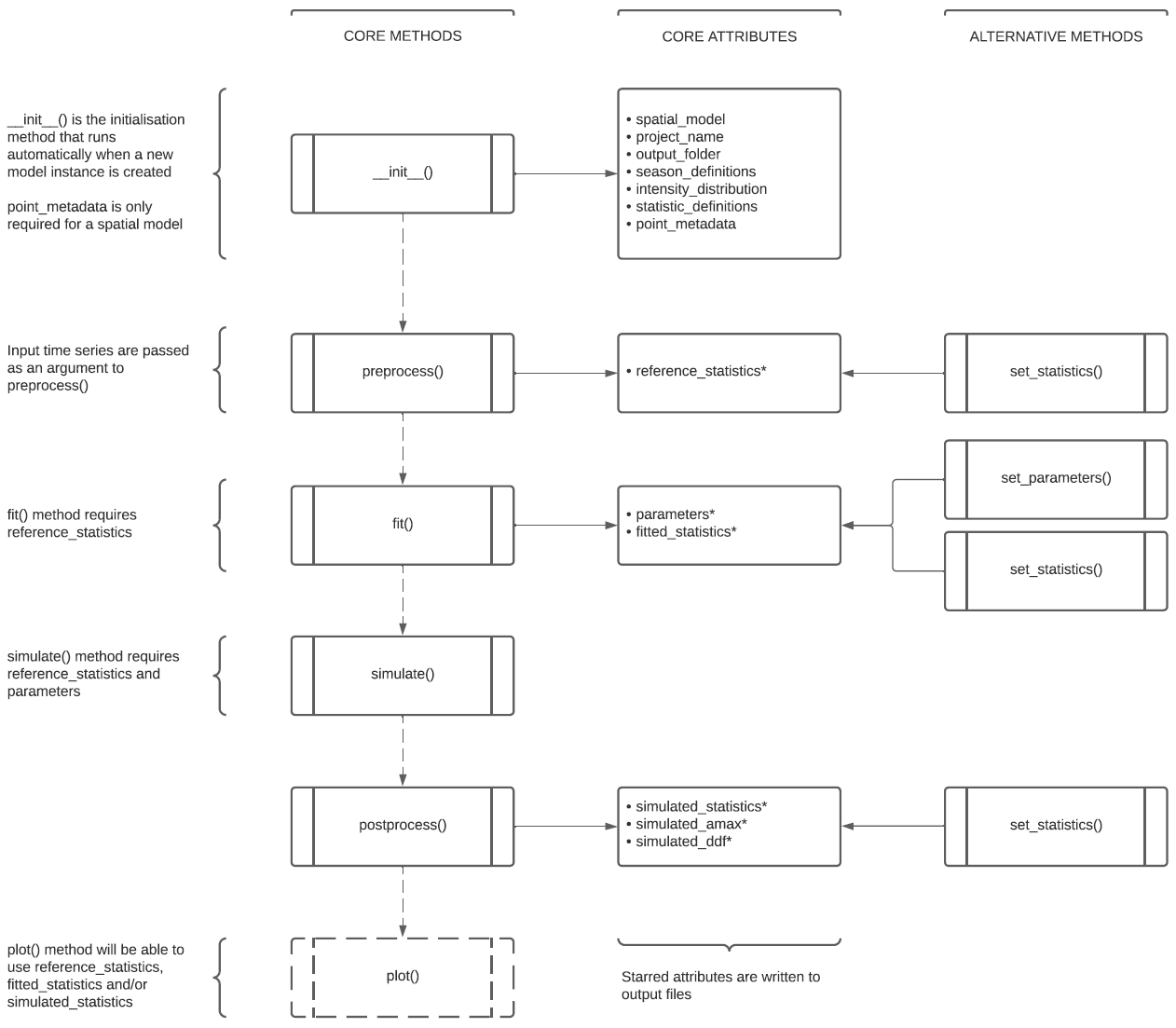
The diagram indicates the “CORE ATTRIBUTES” that are set or updated when
each method is run (effectively the outputs of calling the method). For
example, the diagram indicates that the preprocess() method sets or
updates the reference_statistics attribute. The fit() method sets or
updates the parameters and fitted_statistics attributes.
A few points are worth noting:
The initialisation (
__init__()) method sets many of the attributes we need upfront.Some methods require particular attributes to have been set/updated before they are run. For example, the
fit()method requires thereference_statisticsattribute, which is set/updated by thepreprocess()method.Each method may take other arguments to help perform its task, even though these arguments are not set as model attributes. For example, the
simulate()method takes an argumentsimulation_lengthto determine the number of years that should be simulated.In addition to simulated time series files created by the
simulate()method, other methods generate output files that can be inspected or even modified.
Method Details
Details of the options available for the different methods of RainfallModel
are currently given in the example notebooks, as well as on the
rainfall model Method Options page. Please also see the
Rainfall Model API documentation for further details.
Alternative Workflows
In some cases it might be useful to follow an alternative workflow. For example, if model fitting was conducted in a previous session and we are happy with the parameters, we do not want to run the fitting method again in order to do some additional simulations. In this case we want to set the required attributes directly and go straight to fitting.
The diagram above shows some “ALTERNATIVE METHODS” that allow us to do this.
These methods are set_statistics() and set_parameters(). Both methods
can read from .csv files output by other methods (e.g. preprocess() and
fit() methods). These methods thus add flexibility to how the model can
be used.
For example, we could use something like:
import rwgen
# Initialise rainfall model
rainfall_model = rwgen.RainfallModel(
spatial_model=False,
project_name='brize_norton',
)
# Set reference statistics from a file written during a previous session
rainfall_model.set_statistics(
reference_statistics='./output/reference_statistics.csv',
)
# Set parameters from a file
rainfall_model.set_parameters(
parameters='./output/parameters.csv',
)
# Simulate five realisations of 1000 years at an hourly timestep
rainfall_model.simulate(
simulation_length=1000,
n_realisations=5,
timestep_length=1,
)
It is also possible to do things like run a method more than once using
different optional arguments. For example, if we ran fit() but decided
to run it again with different parameter bounds, we could make a second call
to fit(). The only thing would be to specify different output file
names to avoid previous output being overwritten (if we wanted to keep it).